

22일 과학기술정보통신부 고위 관계자는 “스탠포드대 AI보고서의 오류를 바로잡기 위해 강창묵 과학기술정보통신 영사에게 (스탠퍼드대) 접촉을 부탁했다”면서 “스탠포드대에서 서베이하는 방법이 잘못된 것 같아 비공식적으로 접촉하고 있는 것으로 알고 있다”고 밝혔다.
강 영사는 지난해 샌프란시스코 총영사관에 부임했으며 실리콘밸리를 포함한 샌프란시스코 베이 지역에서 한국의 정보기술(IT) 기술경쟁력을 인정받을 수 있도록 노력하는 업무를 하고 있다. 한국투자공사(KIC) 실리콘밸리와 대한무역투자진흥공사(KOTRA) IT지원센터 지원 업무도 맡고 있다.
|

앞서 스탠포드대는 15일 공개한 ‘AI 인덱스 2024’ 보고서에서 지역별 FM의 수를 공개하면서 미국이 109개로 가장 많고, 중국과 영국, 아랍에미리트(UAE)가 각각 20개와 8개, 4개로 집계됐다고 전했다. 이밖에도 10개국 정도가 파운데이션 모델(FM)을 갖고 있는 것으로 표기됐지만 보고서에 한국은 없었다. ‘지역별 주목할 만한 머신러닝 모델’의 수에 있어서도 미국이 61개로 가장 많았고, 중국(15개)과 프랑스(8개), 이스라엘(4개) 등의 순으로 집계됐으나 한국은 거론되지 않았다.
이에 일부 언론이 보고서를 인용해 한국의 AI 수준이 미진하다는 요지로 보도하자 과기정통부는 해당 보고서 원문 56페이지에 저자들이 “한국과 중국 같은 특정국가 모델을 축소해서 보고했을 가능성이 있다”고 기재됐음을 언급하며 사실이 아니라고 반박했다. 특히 해당 보고서의 AI 관련 지표에서 한국의 AI 특허 수가 10년 전보다 38배 이상 증가했다는 내용 등이 담겼다는 점도 지적했다.
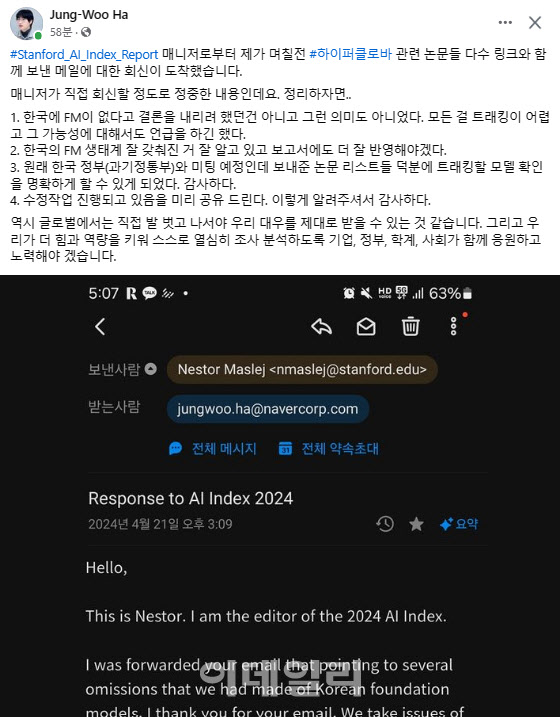
하 센터장은 자신의 페이스북 게시물을 통해 스탠포드대 매니저의 회신 내용을 알렸다. 게시물에서 해당 매니저는 “‘한국에 FM이 없다고 결론을 내리려 했던 것이 아니다. 모든 모델을 추적하기 어려웠다”며 “보내준 논문 리스트들 덕분에 추적할 모델을 명확히 확인할 수 있게 됐다. 관련 보고서의 수정 작업이 진행되고 있다”고 밝혔다.
FM이란 생성형AI를 만드는 기반 모델을 의미한다. 파운데이션모델이 중요한 이유는 연동비가 들지 않고 확장성이 좋기 때문이다. 챗GPT를 사용할 경우 파운데이션 모델 사용료를 오픈AI에 내야 한다. 오픈AI ‘GPT-4 터보’ 기준으로 1토큰(영어 기준 4개 글자 정도)은 출력 0.00001달러, 입력 0.00003달러다. 국가 차원에서는 빅테크들의 클라우드 서버에 자국 데이터를 주지 않아도 되기에 데이터 주권을 지킬 수 있다.
|
이번 스탠포드 AI 인덱스 보고서 오류와 관련한 일련의 소동을 통해 업계 안팎에서는 정부 뿐만 아니라 기업, 학계, 언론도 IT 외교력을 강화하기 위해 더 많은 노력을 기울여야 한다는 지적이 나온다.
AI 인덱스 보고서를 발표한 스탠포드대 HAI 연구소는 ‘FM’이라는 용어를 사실상 논문에서 처음 쓴 리시 봄마사니(Rishi Bommasani)가 근무하고 있다. 봄마사니는 지난해 3월에 발표한 ‘생태계 그래프: 파운데이션 모델의 사회적 입지(Ecosystem Graphs: The Social Footprint of Foundation Models)’라는 논문을 통해 GPT, 제미나이 등 불투명한 AI 파운데이션 모델의 데이터셋, 영향력, 제품 특징 등을 정리해 주목받았다. 그런데 이번에는 실수를 범한 것이다.
국내 한 AI 전문가는 “리시 봄마사니 등이 전세계 모델 중 일부만 서베이하면서 한국의 파운데이션 모델을 제외한 것으로 안다”고 말했다.
AI 전문가는 “네이버(NAVER(035420))와 LG(003550) AI 연구원, 카카오브레인, KT(030200) 정도가 일단 파운데이션 모델을 보유하고 있다고 볼 수 있다”며 “다만 KT의 경우 허깅페이스에는 올라가 있지만 글로벌로 발표된 사례는 없다. 솔트룩스나 코난테크놀로지는 자체 기술은 있지만 애플리케이션 프로그래밍 인터페이스(API)를 외부에 공개한 적은 없는 상황”이라고 평했다.






![[포토] '금융권 공감의 장' 인사말하는 이병래 회장](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112600936t.jpg)
![[포토]경북 국립의대 신설 촉구, '참석자들에게 인사하는 한동훈'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112600846t.jpg)
![[포토]손태승 전 회장, 영장실질심사 출석](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112600794t.jpg)
![[포토]정윤하 등장](https://spnimage.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112600056t.jpg)
![[포토]내년에 또보자 가을](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112600715t.jpg)
![[포토]민주당 민생연석회의 참석하는 이재명 대표](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112600655t.jpg)
![[포토] '소상공인 힘보탬 프로젝트' 발표](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112600583t.jpg)
![[포토]정부, 국무회의에서 세번째 `김여사 특검법` 거부권 건의 의결](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112600579t.jpg)
![[포토] 이즈나 데뷔](https://spnimage.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112500181t.jpg)
![[포토]첫 싱글 '라스트 벨'로 돌아온 TWS](https://spnimage.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112500118t.jpg)




![“270만원 화웨이 신상폰 살 수 있어요?” 中매장 가보니[르포]](https://image.edaily.co.kr/images/vision/files/NP/S/2024/11/PS24112601335h.jpg)