
같은 날 이재용 삼성전자 회장은 저커버그 내외와 만찬을 하면서 AI반도체 협력을, 조주완 LG전자 사장은 저커버그와 만나 XR 사업 협력을 논의했죠. 이를 고려하면, 정부가 삼성과 LG의 메타와의 협력을 측면으로 지원한 셈입니다.
|

이처럼, 글로벌 빅테크와의 파트너십은 한국의 IT 기업들의 생존 전략으로 부상하고 있습니다. 지난 주에 개최된 세계 최대 이동통신 전시회인 모바일 월드 콩그레스(MWC)에서도 마찬가지였습니다.
SKT는 휴메인(Humane) 및 퍼플렉시티(Perplexity)와 개인형 AI 비서 시장에서 손잡았고, KT와 LG유플러스는 아마존웹서비스(AWS)와 협력해 아마존 클라우드를 기반으로 생성형 AI 서비스를 내놓기로 했습니다.
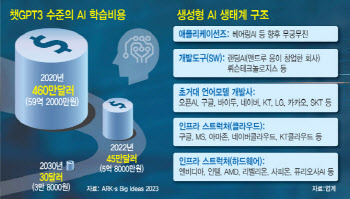
국내 통신사들이 빅테크들과 손잡는 것은 수십조 원을 투자하여 글로벌 빅테크와 경쟁할 수 있는 초거대 AI(Large Language Model, LLM)를 개발하는 게 쉽지 않기 때문입니다.
KT나 SKT처럼 자체 LLM을 개발한다 해도, 구글·마이크로소프트·오픈AI와 직접 경쟁하긴 어렵습니다. 그래서 규모는 작지만 특화된 영역에 집중하고 있습니다.
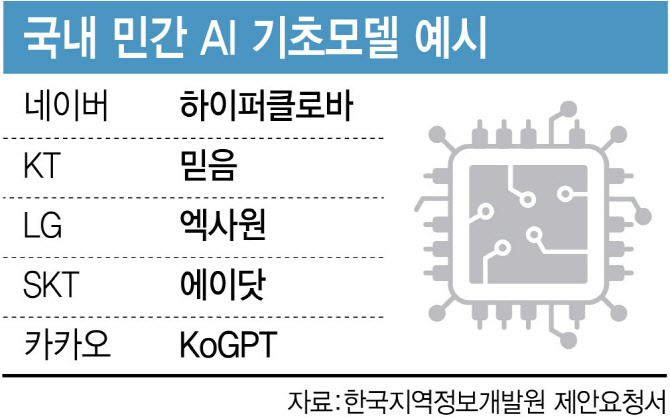
네이버는 ‘하이퍼클로바X’라는 LLM을 개발해 채팅봇, 검색 등에 적용하고 있습니다. 비록 빅테크 기업들에 비해 인력과 자본이 부족하긴 하지만, 네이버는 묵묵히 자체 LLM을 개발하고 이를 자사 클라우드에 적용하여 다양한 서비스 모델을 구축하고 있습니다.
네이버는 한글과컴퓨터와 함께 ‘아래한글 문서 기반의 생성형 AI 서비스’를 개발 중인데, 이는 ‘MS 코파일럿 365’와 시장에서 경쟁할 서비스죠.
네이버 외에도 AI 기초 모델, 일명 파운데이션 모델을 개발하는 회사들이 몇몇 있습니다. 그러나 네이버처럼 모든 영역을 아우르며 개발하는 기업은 드뭅니다.
|
|

|

대한민국에 자체 거대언어모델(LLM)이 존재한다는 게 어떤 의미냐고요? 한국의 AI 산업을 키우는데 필요한 일이고, 대한민국의 데이터 주권을 지키는 일이라고 생각합니다.
전문가들은 오픈소스 기반의 LLM을 파인튜닝(미세조정)해 쓰는 것이나, 오픈AI나 구글의 LLM을 가져다가 응용 서비스를 만드는 것도 중요하나, 한국의 독자적인 LLM이 없다면 장기적으로 봤을 때 산업의 경쟁력이 훼손할 수 있다고 경고합니다.
유창동 KAIST 교수(전 한국인공지능학회장)는 “만약 트럼프 대통령이 나와 챗GPT 수출을 금지하면 어떻게 될까?”라면서 “이제 입장을 정해야 한다. 대한민국 자체 LLM이 필요하다”고 말했습니다.
그러나 우주 개발처럼 정부가 주도하여 대한민국 자체 LLM 개발을 추진하는 것에는 이견이 있습니다. IT 산업의 역동성을 고려하면 국가 주도의 프로젝트가 성공하기 어려울 수 있죠.
따라서 정부는 우리 기업이 초거대 AI를 개발하는 데 광범위하게 지원했으면 합니다. 특히 파운데이션 모델을 개발하는 기업에 대한 특별한 관심과 진흥 정책이 필요하다고 생각합니다. 미래 먹거리인 로봇과 신약 개발에서 AI 기술 경쟁력이 성패를 좌우할 것이기 때문입니다.
‘네이버 1784’는 세계 최초의 로봇 친화형 빌딩으로, AI와 로봇 기술이 집중된 곳입니다. 숫자 1784는 최초의 산업혁명이 시작된 해에서 따왔다고 하죠.
올해는 윤석열 대통령이 이런 혁신적인 시설을 방문하여 한국의 자체 LLM 을 개발하는 기업들을 격려해주기를 기대합니다.









![[포토]명동성당 성탄 대축일 미사](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500276t.jpg)
![[포토]다시 돌아온 있지 리아](https://spnimage.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500136t.jpg)
![[포토]크리스마스엔 스케이트](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500245t.jpg)
![[포토]37번째 거리 성탄예배 열려 방한복·도시락으로 사랑 나눔](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500231t.jpg)
![[포토]조국혁신당 공수처 앞에서 기자회견](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500219t.jpg)
![[포토]우리 이웃을 위한 크리스마스 선물](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500173t.jpg)
![[포토]메리크리스마스](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400797t.jpg)
![[포토]즐거운 눈썰매](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400779t.jpg)
![[포토]취약계층 금융 부담 완화, '인사말하는 이재연 원장'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400633t.jpg)
![[포토]국민의힘 의원총회, '모두발언하는 권성동 원내대표'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400506t.jpg)
![[포토]윤이나,후배 양성을 위해 2억원 기부했어요](https://spnimage.edaily.co.kr/images/vision/files/NP/S/2024/12/PS24122600088h.jpg)


![GTX 킨텍스역 28일 개통, 서울역까지 소요 시간 '1시간 → 16분' [MICE]](https://image.edaily.co.kr/images/vision/files/NP/S/2024/12/PS24122600326h.jpg)
