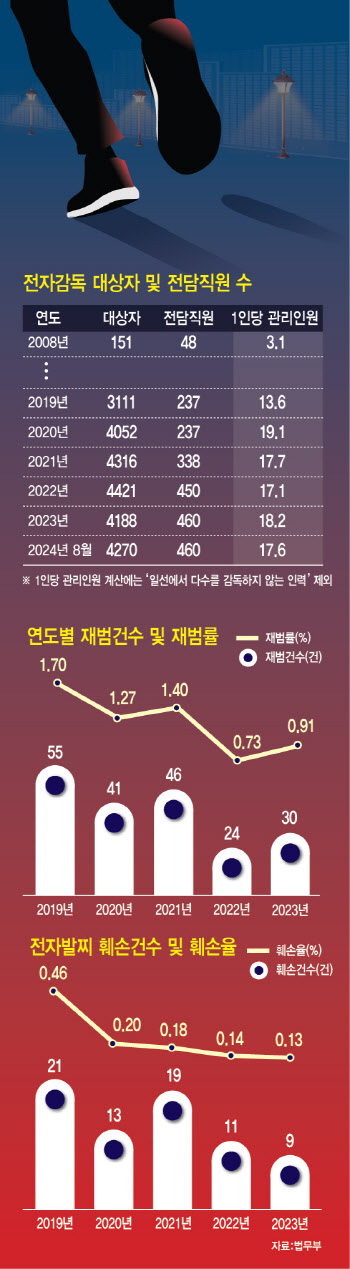
|
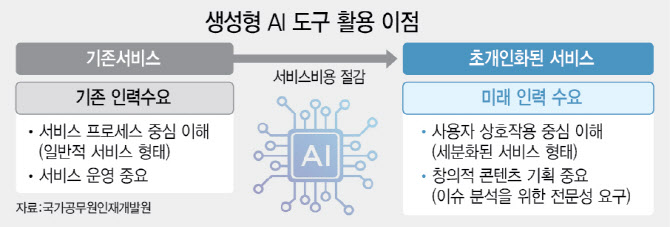
이에따라 한국원자력연구원, 한국전자통신연구원, 한국기계연구원 등은 자체적으로 내부 시스템에 특화된 생성형AI를 개발 중이다.
4일 과학기술계에 따르면 출연연들은 메타가 개발한 오픈소스 거대언어모델(LLM)인 모델인 ‘라마(Llama 2)’ 등 허깅페이스에 올라온 오픈소스 모델에 내부 문서 등을 학습 시켜 출연연용 특화 모델을 개발중이다.
민옥기 한국전자통신연구원 초지능창의연구소장은 “허깅페이스처럼 인공지능 개발자 커뮤니티 등을 참고해 국내 모델을 만들고 추가 학습을 해서 특화된 모델을 내부용으로 쓰고 있다”며 “(외산 프로그램 대비) 컴퓨팅 파워가 밀리기 때문에 모델 정확도에서는 차이가 있어 아쉬움은 있지만 큰 모델들과 유사한 정확도를 가질 수 있는 프로그램을 개발하기 위해 노력하고 있다”고 설명했다.
유용균 한국원자력연구원 인공지능응용연구실장도 “공개 모델을 기반으로 특수한 목적으로 사용될 수 있는 자체 모델을 개발하는 추세”라며 “한국어 데이터를 넣고 추가 보완작업을 해서 가치 있게 만드는 작업을 하고 있다”고 설명했다. 유 실장은 “가령 원자력연에서 대국민 서비스를 위한 챗봇을 개발하는 하고, 원자력 법령과 같은 문서를 학습시키기 위한 내부 모델도 초기 단계이지만 개발하고 있다”고 설명했다.
한편, 출연연이 국가사회적으로 중요한 임무를 하는 만큼 과학 인재들의 작업 효율을 높이기 위해 정부가 기업용 생성형 AI 솔루션을 도입할 수 있도록 지원해야 한다는 의견도 있다. 출연연에서 근무하다 창업한 한 기업 대표는 “출연연에서 파워포인트를 이용하는 것과 달리 상용 생성형AI 모델을 이용해 순식간에 기획안과 그림을 그리는 것을 보여주자 연구자들이 놀라워하더라”면서 “인공지능 분야에서는 개방과 협력이 추진되는 상황에서 보안과 예산 문제도 중요하지만, 고급 인력들의 작업 효율을 높이도록 외부 생성형 AI를 도입하도록 지원하는 방안도 함께 고민했으면 한다”고 말했다.





![[포토] 비만치료제 '위고비' 입고 안내문](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/10/PS24101800631t.jpg)
![[포토]이창수 '김건희 여사 압수수색 영장 청구 건은 코바나컨텐츠 사건'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/10/PS24101800621t.jpg)
![[포토]국정감사 출석한 이창수 서울중앙지검장](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/10/PS24101800449t.jpg)
![[포토]최고위, '모두발언하는 김민석 최고위원'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/10/PS24101800388t.jpg)
![[포토]'국정감사대책회의 참석하는 추경호'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/10/PS24101800280t.jpg)
![[포토]정남수,거리 확인은 정확하게](https://spnimage.edaily.co.kr/images/Photo/files/NP/S/2024/10/PS24101700579t.jpg)
![[포토]브룩 핸더슨,힘찬 티샷](https://spnimage.edaily.co.kr/images/Photo/files/NP/S/2024/10/PS24101700443t.jpg)
![[포토]포니정 혁신상 시상식 참석한 한강](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/10/PS24101701182t.jpg)
![[포토] 이상희 '정교한 컨트롤로 선두 등극'](https://spnimage.edaily.co.kr/images/Photo/files/NP/S/2024/10/PS24101700251t.jpg)