[IT벤치마크팀 닥터몰라] ▶
1편에서 이어집니다.
엔비디아의 승부수 ‘튜링’ 보기
1부①
▶보기 / 1부②
▶보기 / 2부①
▶보기 / 2부②
▶보기 | | 케플러(Kepler). 닥터몰라 제공 |
|
냉·온탕을 오간 Fermi 아키텍처의 유산을 물려받은 Kepler 아키텍처는 제1목표를 전력효율의 극대화에 두었다. 이를 위해 Tesla / G80 세대부터 내려온 유산인 2~2.5배속 쉐이더 클럭을 폐지, 칩 전체의 작동 속도를 저클럭화하고 이를 상쇄하기 위해 엄청난 수량의 ALU를 집적한 것이 Kepler 세대의 특징이다.
Kepler 아키텍처로서 최초로 상용화된
는 1536:128:32의 규모를 자랑했다. GF100/110과 비교했을 때 ALU가 200%, 텍스처 유닛은 100% 증가했으며, 2배속 쉐이더 클럭이 적용되지 않는 것을 감안하더라도 제조공정의 미세화로 기본 클럭 자체가 50% 향상되어 ALU 성능이 125%, 텍스처 성능은 50% 향상되었고 ROP 성능은 같은 수준을 유지하고 있다. 한 해 뒤 등장한 Kepler 아키텍처의 빅 칩, GK110의 유닛 구성은 2880:180:48에 달한다.
Kepler의 GPU-GPC-SM 구조는 Fermi는 물론 Fermi Refresh와도 다르다. Kepler SM은 4 스케줄러 / 192 ALU / 16 텍스처 유닛을 탑재해 GF104/114 대비 각각 1배 / 4배 / 2배에 달하며, 특히 SM당 스케줄러 개수가 그대로 유지되었으나 명령어를 발행하는 디스패치 유닛이 스케줄러당 1->2개로 늘어 프론트엔드가 2배 확장된 효과를 갖는다. GK110은 5 GPC에 걸친 15 SM 구조로, 5개의 래스터 엔진(클럭당 80개 래스터 공급) / 60 스케줄러 / 120 디스패치 유닛 등 당시까지 출시된 GPU 중 가장 강력한 프론트엔드를 가졌다.
이렇듯 큰 변화가 가능했던 것은 Fermi 아키텍처 이후 처음으로 풀 노드 체인지(40->28nm)가 동반되었기 때문이다. 반면 Kepler의 후속으로 투입될 Maxwell 아키텍처는 제조공정을 그대로 유지하며, 아키텍처 혁신만으로 성능향상과 전력효율 향상을 동시에 추구해야 하는 난제에 처했다. 엔비디아의 해답은 GF100/110 -> GF104/114에서 학습한, 유닛 구성비율 변경과 FP64 연산 성능의 삭감이었다.
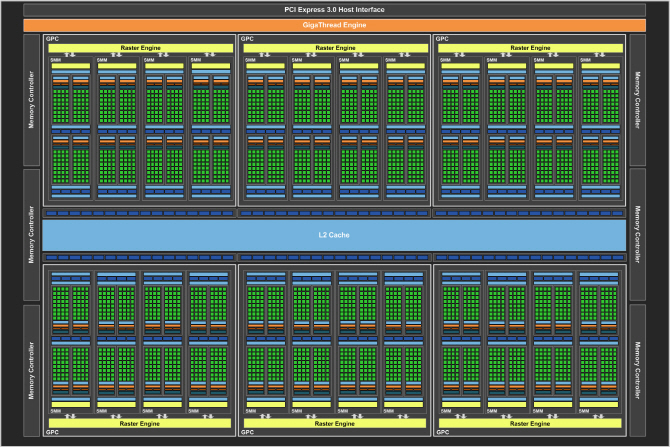 | | 맥스웰(Maxwell) |
|
Maxwell 아키텍처는 SM당 4 스케줄러 / 8 디스패치 유닛 / 16 텍스처 유닛이 탑재되는 점에서 Kepler 아키텍처와 같으나 ALU 개수가 Kepler SM의 2/3 수준인 128개로 대폭 줄어들었다. 전체적으로는 연산 유닛 대비 텍스처 유닛 및 ROP의 비율이 상향되어 게이밍 성능이 크게 오른다. 또한 FP64 연산 자원을 Kepler의 1/16 수준으로 삭감(이는 GF100/110 -> GF104/114의 변화보다 더 큰 폭이다), 제조공정의 한계에서 트랜지스터를 그야말로 쥐어짠 결과물이랄 수 있다.
과 의 성능 관계에서 이 점은 뚜렷하게 드러난다. 둘의 SM 개수는 각각 16개 vs 15개로 엇비슷하나 ALU는 2048개 vs 2880개로 GeForce GTX 980쪽이 훨씬 적다. 그럼에도 게이밍 성능은 GeForce GTX 980이 더 높게 나타나는데, 이는 연산 유닛에서 절약한 자원으로 ROP를 확충했기 때문이다(64개 vs 48개).
느슨하게 보아, Kepler 아키텍처와 제조공정이 같고 무엇보다 주요 특성을 그대로 계승했다는 점에서 Kepler와 Maxwell 아키텍처의 관계를 Fermi-Fermi Reresh의 그것과 동치시킬 수도 있다. 이 경우 세대 내에서의 역할 교대가 ‘세대간’ 역할 교대로 변화했을 뿐 본질적으로는 같은, 어떤 의미에서의 ‘틱톡’이라고 보는 것도 가능하다. 이 점은 둘의 후속 아키텍처이자 또 한번의 풀 노드 체인지(28nm -> 16nm FF)가 동반된 Pascal에서 더욱 명확해진다.
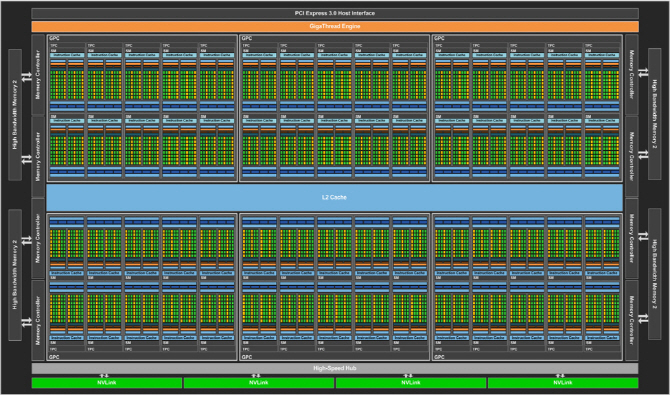 | | 파스칼(Pascal) GP100. 닥터몰라 제공 |
|
 | | 파스칼(Pascal) GP102. 닥터몰라 제공 |
|
Pascal 아키텍처는 강력한 FP64 및 FP16 연산 성능을 갖춘 연산 가속기 으로 처음 상용화되었다. GP100은 로 데스크탑 시장에 출시된 Pascal 세대의 또 다른 빅 칩 GP102와 큰 틀에서 유사하다. FP64 및 FP16연산 성능을 제한하고, 메모리 인터페이스를 4096비트 HBM2에서 384비트 GDDR5X로 변경했을 뿐인 것 같다.
그러나 둘은, 이후 같은 세대 내에서 컴퓨팅용과 게이밍용 아키텍처를 완전히 분리(Volta와 Turing)해내기 위한 예행 연습이 아니었을까 여겨질 만큼 큰 차이가 있다.
GP102 이하의 Pascal은 큰 틀에서 Kepler-Maxwell에서 이어져 내려온 SM 설계철학 대부분을 계승하고 있으며 특히 Maxwell SM과 대동소이하다. GP102의 경우 5 SM과 하나의 래스터 엔진이 GPC를 구성하며, GPU 전체는 이러한 GPC 6개로 구성된다. Maxwell과 다른 점은 GPC를 구성하는 SM 개수가 4->5개로 변화한 것밖에 없다.
반면 GP100은 SM 구성이 Maxwell / Pascal GP102의 정확히 절반으로 줄어들었다. 다만 GPC를 구성하는 SM 개수가 2배 증가하여 GPC 레벨에서의 각 유닛 총수는 GP102와 같고, GP100 GPU 전체에 탑재된 GPC의 개수 역시 6개로 동일하여 거시적인 레벨에서 차이가 은폐될 뿐이다.
이를 예행 연습으로 표현한 이유는, 다름아닌 Volta 아키텍처가 GP100과 같은 SM 구조를 공유하기 때문이다. 또한 Volta는 Kepler 아키텍처부터 1:2를 고수해 온 스케줄러-디스패치 유닛 비율을 스케줄러를 두 배 늘림으로써 1:1로 끌어올렸다.
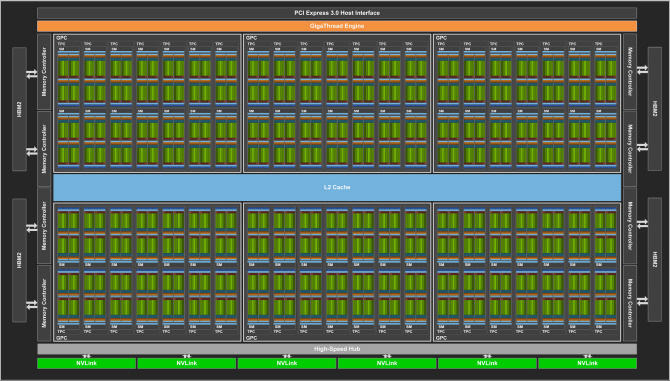 | | 볼타(Volta). 닥터몰라 제공 |
|
Pascal 아키텍처 기반 메인스트림 칩 GP106은 이제까지의 어떤 엔비디아 GPU에도 없던 재미있는 특성을 갖는다. 풀 칩 기준으로도, 래스터 엔진의 공급량이 ROP의 처리량에 못 미치게 (32 < 48) 설계된 것이다. 결과적으로 48 ROP를 모두 활용하지 못하게 되는데, 이러한 설계가 단순히 체급 차등화를 위함인지, 차세대 워크로드(ROP를 활용한 안티알리아싱 등)의 밸런스를 고려한 거시적 안목의 조치인지 아직은 가늠할 수 없다.
빅 칩들인 GP100, GV100 역시 래스터 엔진의 공급량이 ROP의 출력량에 못 미치는 (96 < 128) 구조이며 후술할 Turing 아키텍처 기반 에 사용된 TU106 칩 역시 래스터 엔진이 ROP를 못 따라가는 (48 < 64) 구조이다.
구조적 문제가 아니더라도 (의도적으로?) 래스터 엔진을 제한함으로써 상위 SKU와의 성능 격차를 벌리는 경우가 있다. 에 사용된 GP104 칩은 4 GPC와 64 ROP 구성으로, 그 자체로는 래스터 엔진과 ROP가 완전히 균형잡힌 사양이나, GeForce GTX 1070을 파생시키며 GPC 하나를 완전히 비활성화해 래스터 엔진의 공급량이 ROP의 출력량에 못 미치게 (48 < 64) 된다.
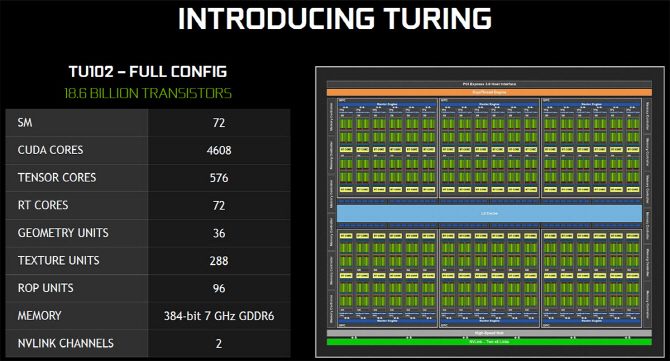 | | 튜링(Turing). 닥터몰라 제공 |
|
Turing 아키텍처는 많은 부분 Pascal(GP100) / Volta 아키텍처의 그것과 닮아 있으나 완전히 같지는 않다. 무엇보다 큰 차이점은 G80 이래 불변의 기조였던 ‘통합 쉐이더로의 통합’을 뒤집고, 전용 유닛을 대거 탑재한 것이다. 딥러닝 추론을 위한 ‘텐서코어’, 실시간 레이 트레이싱을 위한 ‘RT코어’, 심지어 ALU 파이프라인을 확장해 32비트 정수(INT32) 포맷을 지원하는 정수 연산 유닛을 기존 ALU와 동수로(!) 탑재했다. 연산 유닛의 총 개수는 TU102 칩 기준 무려 1만 개를 넘는다.
비록 아키텍처 이름은 분리되었지만 같은 항렬의 손윗 형제자매뻘인 GV100과 TU102를 비교해 보면 트레이드오프를 알 수 있다. 둘은 모두 6개의 GPC를 탑재, GV100은 GPC당 14 SM으로 총 84 SM / 5376 ALU 구성이며 TU102는 GPC당 12 SM으로 총 72 SM / 4608 ALU 구성이다. FP64 연산 유닛을 제거하고 SM 개수를 12.5% 줄여 얻어낸 여력을 RT코어 등의 구현에 재투자한 것이다. 둘의 면적은 815mm2 vs 754mm2로 한 자릿수 % 차이에 불과하다.
그러나 투입한 만큼의 효율이 드러나고 있느냐면 아직은 아닌 것 같다. 당장 효과를 보기 힘든 텐서코어와 RT코어를 제외하더라도, 기존 ALU와 똑같은 수의 정수 연산 유닛을 탑재했음에도 엔비디아가 밝힌 ALU 스루풋은 기존 대비 36% 향상에 그친 반면 소비전력은 Pascal 세대보다 전반적으로 증가한 경향을 보인다. Turing이 제2의 G80이 될지, NV30 / Fermi의 전철을 밟을지는 그리 머지 않아 판가름 날 것이다. (2부 끝)
▲닥터몰라 소개= 다양한 전공과 배경을 가진 운영진이 하드웨어를 논하는 공간이다. 부품부터 완제품에 이르는 폭 넓은 하드웨어를 벤치마크하는 팀이기도 하다. 데이터베이스를 구축해 이미 알려진 성능의 재확인을 넘어 기존 리뷰보다 한층 더 깊게 나아가 일반적으로 검출하기 어려운 환경에서의 숨은 성능까지 예측가능한 수리모델을 개발하고 있다.
필진으로 이대근 씨(KAIST 수리과학 전공)와 이진협 씨(성균관대학교 생명과학 및 컴퓨터공학 전공), 이주형 씨(백투더맥 리뷰 에디터/Shakr 필드 엔지니어) 등이 참여한다.









![[포토] 원·달러 환율 오를까?](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112900849t.jpg)
![[포토] 폭설 피해](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112900576t.jpg)
![[포토] 주식시장 활성화 테스크포스-경제계 간담회](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112900547t.jpg)
![[포토]최재해, '정치적 탄핵 매우 유감...자진 사퇴 생각 없다'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112900431t.jpg)
![[포토]'모두발언하는 이재명 대표'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112900370t.jpg)
![[포토]이데일리 퓨처스포럼 송년회 무대](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112801622t.jpg)
![[포토]용산국제업무지구 개발계획 공동협약식에서 협약서 서명](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24112801123t.jpg)

![강 건너고 짐도 나르고…‘다재다능’ 이상이의 무한변신 차는[누구차]](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24113000161h.jpg)


