
인간이 모방할 수 없는 ‘고도로 정밀한’ 계산을 수행하는 전통적 슈퍼컴퓨터, 즉 계산기로서의 기대역할은 어느 순간 ‘덜 정밀하더라도 동시다발적인’ 막대한 연산을 누적해 인간 두뇌의 학습을 모방하는 기계학습으로 바뀐 바 있다.
◇인텔, 아톰 CPU 기반 ‘제온파이’ 가격 대대적 인하
CPU에 뿌리를 둔 인텔답게 ‘GPU형’ 연산 가속장치에도 그들만의 색채를 가미했다. 통상적인 CPU보다는 개별 코어의 성능이 떨어지지만 GPU보다는 높고, 소비전력이 낮은 장점을 가진 ‘아톰’ 코어를 60-70개 집적해 전통적인 CPU와 전통적인 GPU 그 중간쯤 어딘가를 겨냥한 것이다. 이 제품을 우리는 ‘제온 파이’라고 부른다.
최근 인텔은 제온 파이의 가격을 대폭 인하했다. 최상위 모델의 가격이 6500~6700달러에서 3200~3300달러로 인하폭은 무려 절반을 상회한다. 이외에도 3800달러 모델이 1900달러로, 2500달러인 최하위 모델이 1800달러로 인하되는 등 라인업 전반에 걸쳐 가격 조정이 있었는데, 재미있는 사실은 이 모든 과정이 소리소문없이 ‘전격적’으로 단행되었다는 것이다.
|

나이츠 밀은 기계학습·인공지능 시장을 겨냥해 16비트 반정밀도(Half Precision, FP16), 8비트 정수(INT8) 연산성능을 강화한 것이 특징이다. 반면 현세대 제온 파이는 전통적 슈퍼컴퓨터 시장을 겨냥해 64비트 배정밀도(Double Precision, FP64) 연산성능이 좋다. 이들은 통상적인 세대교체와 달리, 서로 다른 시장을 겨냥하는 것이 뚜렷하기에 당분간 상호보완적 라인업을 구축해 공존할 것으로 예상된다.
|

제조공정을 진화시키지 않으면서 더 낮은 정밀도의 연산성능을 발전시키는 방향은 두 세대 전 엔비디아가 추구한 것과 같다. 당시 엔비디아는 TSMC의 28nm 제조공정에 발목잡힌 채 두 세대의 GPU 개발을 끌었는데, 배정밀도 성능을 중시한 ‘케플러’의 후속으로 이를 제거한 ‘맥스웰’을 투입한 한편 요구되는 정밀도가 낮은 모바일용 맥스웰에 반정밀도 가속 기능을 파일럿으로 도입해본 경험이 있다.
◇인텔 나이츠밀과 비슷한 결을 가진 AMD ‘베가’
|

이렇듯 인텔과 AMD는 특정 정밀도의 연산성능에 특화된 칩을 먼저 내놓고, 높은 정밀도와 낮은 정밀도 양쪽 모두에 대응하는 칩을 후속으로 내놓는 단계별 접근을 취하는 점에서 닮아 있다. 제조공정이 두 세대 지연된 끝에 차차기 제품(나이츠 힐, 나비)이 도래할 시기에나 신공정을 도입하는 것도 우연의 일치이겠지만 같다.
한편, 오늘날 엔비디아는 이들과 대조적인 접근법을 취하고 있다. 지난달 공개된 차세대 GPU ‘볼타’는 반정밀도 및 8비트 정수연산 가속을 지원할 뿐만 아니라 칩 내부에 일종의 행렬연산용 고정기능 하드웨어인 ‘텐서 코어’를 내장해 행렬연산을 더욱 빨리 수행하는 것이 특징이다.
|
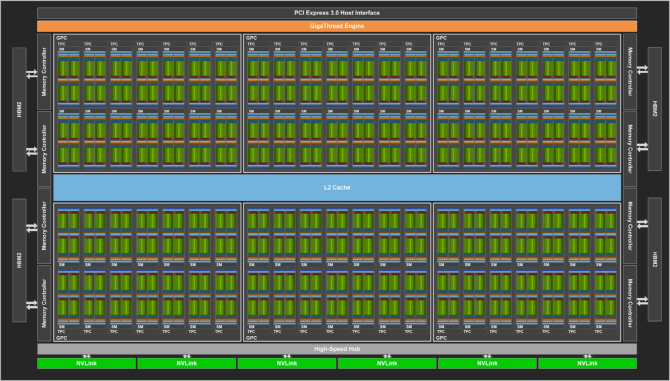
이는 앞서 케플러-맥스웰 과도기에 배정밀도 연산성능을 들어내버린 것과는 전혀 다른 움직임이다. 현세대 ‘파스칼’ GPU의 경우 엔비디아는 아예 설계노선이 전혀 다른 두 칩 GP100과 GP102를 투 톱으로 내세우며 GP100은 배정밀도와 반정밀도 연산에 특화시키고, GP102는 8비트 정수연산에 특화시키는 대신 반정밀도 성능을 의도적으로 제한하는 쌍봉형 라인업을 구축한 바 있다. 그러나 볼타에서는 어떤 수준의 정밀도에서도 연산성능을 희생시키지 않은 것이다.
다만 이러한 접근법의 차이를 단순히 서로 반대되는 것이라고만은 볼 수 없기도 하다. 앞서 언급했듯 엔비디아 역시 두 세대 전에는 인텔, AMD와 같은 시행착오를 겪은 바 있고 그로부터 도출된 것이 지금의 행보일 것이니 말이다. 지금 당장의 단면으로 보아 대척점에 선듯한 인텔·AMD와 엔비디아의 접근법 차이는 단지 시간차를 두고 반복되는 역사의 흐름이었을 뿐일지 모른다.






![[포토]메리크리스마스](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400797t.jpg)
![[포토]즐거운 눈썰매](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400779t.jpg)
![[포토]취약계층 금융 부담 완화, '인사말하는 이재연 원장'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400633t.jpg)
![[포토]국민의힘 의원총회, '모두발언하는 권성동 원내대표'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400506t.jpg)
![[포토]윤석열 대통령 탄핵심판 첫 변론 준비기일 27일 예정대로 진행](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400433t.jpg)
![[포토]'더불어민주당 원내대책회의'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400387t.jpg)
![[포토]국무회의 입장하는 한덕수 권한대행](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400378t.jpg)
![[포토]은행권 소상공인 금융지원 간담회](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122300609t.jpg)
![[포토]인사청문회 출석한 마은혁 헌법재판관 후보자](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122300404t.jpg)
![[포토]아침 영하 10도, 꽁꽁 얼어붙은 도심](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122300843t.jpg)




