[이데일리 김혜선 기자] 인공지능(AI)의 등장 이후 인간의 사고 능력을 평가하는 각종 시험에서 AI 챗봇이 줄줄이 고득점을 받는 가운데, 올해 대학수학능력시험 국어영역에서 AI가 만점에 가까운 점수를 받았다. 그동안 복잡한 추론이 필요한 수능 국어에서 AI는 3~9등급 사이 점수를 받았는데 1년 새 AI의 추론 능력이 비약적으로 발전한 것이다.
 | | (사진=깃허브 캡처) |
|
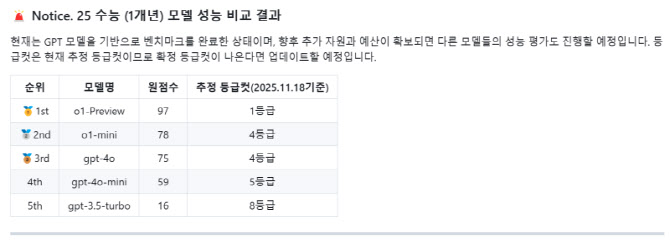
19일 오픈소스 소프트웨어 웹사이트 ‘깃허브(GitHub)’에는 5개의 AI 모델이 2025학년도 수능 국어 영역을 푼 결과가 공개됐다. 5개 모델은 모두 챗GPT를 기반으로 한 모델로, o1 프리뷰와 o1 미니, GPT4o, GPT4o 미니, GPT3.5 터보가 사용됐다.
가장 높은 점수를 받은 모델은 오픈AI의 최신 모델인 o1 프리뷰로 원점수 97점을 받아 추정 등급컷 1등급(18일 기준)을 기록했다. 올해 수능 국어 영역에서 단 1문제만 틀리고 모두 맞힌 셈이다. o1 미니와 GPT4o는 각 78점, 75점을 받아 추정 등급컷 4등급이고, GPT4o 미니는 5등급(원점수 59점), GPT3.5 터보는 8등급(원점수 16점)으로 추정된다.
특히 최신 모델인 o1 프리뷰의 성능 개선이 눈에 띈다. o1 프리뷰는 지난해 수능 국어영역에서도 원점수 88점을 맞아 1등급을 확보했다. GPT4o의 경우 지난해 수능 국어에서 원점수 65점으로 4등급을 받았다. 메타와 구글 등의 생성형 AI들도 최근 10개년 수능 국어영역에서 3등급~9등급 사이를 받았다.
수능 LLM 리더보드를 개발한 Markr AI 연구원 진민성씨는 자신의 블로그에 “이전 수능 국어 10개년 LLM(거대언어모델, Large Language Model) 리더보드에서 성능 비교 결과, 1위를 차지한 gpt-4o가 평균등급 3등급대에 최고 점수는 86점을 차지했다”며 “2025 수능에서 기록한 97점이라는 만점에 가까운 점수는, LLM의 한국어 언어능력이 인간의 퍼모먼스를 뛰어넘을 시기가 머지 않았음을 보여준다”고 부연했다.
한편, 오픈AI가 지난 9월 공개한 최신 모델 ‘O1(오원)’은 인간의 추론 능력에 초점을 두고 개발해온 모델로, 단계적인 사고 과정을 통해 어려운 문제를 해결한다. 오픈AI는 이 모델이 국제수학올림피아드(IMO) 예선 시험에서 이전 모델 정답률이 13%인 데 비해 83%의 정답률을 기록했다고 설명했다.
오픈AI 최고경영자(CEO) 샘 올트먼은 이 모델을 “새로운 패러다임”이라며 “범용의 복잡한 문제를 추론할 수 있는 AI”라고 말했다. 다만 “이 기술이 여전히 결함이 있고, 제한적”이라고 설명했다.







![[포토]명동성당 성탄 대축일 미사](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500276t.jpg)
![[포토]크리스마스엔 스케이트](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500245t.jpg)
![[포토]37번째 거리 성탄예배 열려 방한복·도시락으로 사랑 나눔](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500231t.jpg)
![[포토]조국혁신당 공수처 앞에서 기자회견](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500219t.jpg)
![[포토]우리 이웃을 위한 크리스마스 선물](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122500173t.jpg)
![[포토]메리크리스마스](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400797t.jpg)
![[포토]즐거운 눈썰매](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400779t.jpg)
![[포토]취약계층 금융 부담 완화, '인사말하는 이재연 원장'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400633t.jpg)
![[포토]국민의힘 의원총회, '모두발언하는 권성동 원내대표'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400506t.jpg)
![[포토]윤석열 대통령 탄핵심판 첫 변론 준비기일 27일 예정대로 진행](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/12/PS24122400433t.jpg)